
The difference between Hadoop and Spark is in their preparation, process, management, and analysis of Big Data sets. Big Data consists of large datasets and images. Similarly, these datasets can have a different format and the frameworks collect the data from various sources. However, Big data does not define only the volume of the data.
There are three terms that classify the data in big data. Velocity, Volume, and Veracity. The data volume in big data is in terms of terabytes, petabytes, and so on. Velocity defines the speed of the movement of data. Veracity defines the way that structured and unstructured data is handled.
Various industries like banking, media, healthcare, etc implement the Big Data infrastructure.
Industries use frameworks to handle the processing and storing of big data. Many frameworks handle Big data. For instance, Hadoop, Spark, and Hive are known as popular frameworks.
Difference Between Hadoop and Spark: Which is the better big data framework?
Hadoop
Apache Hadoop is an open-source software programming framework that is for storing and processing large datasets. In addition, these data sets can vary from gigabytes to petabytes of data. Apache built the framework with java programming and some native C code.
Hadoop uses cluster computers to process massive datasets in parallel. Hence, It increases the speed of processing of data.
Apache distributes the Hadoop framework into four main modules:
- Hadoop Distributed File System (HDFS): It is a distributed file system that is designed to run on low-end hardware. In addition, it has a fault-tolerant feature and is suitable for applications having large datasets.
- Yet Another Resource Negotiator (YARN): This framework handles the scheduling of jobs and monitors the cluster node and resource usage.
- MapReduce: This framework is capable of processing large data in parallel with the help of cluster computers.
- Hadoop Common: It has a collection of Java libraries that are used by other modules.
How does Hadoop work?
To manage a large number of data-set is critical and requires heavy machines. Similarly, it is expensive to build big servers that have heavy configurations.
That’s why Hadoop uses the cluster computing technique which is a set of low-end systems. We interconnect these low-end systems and work as a single system. The cluster computer can process the data set in a parallel way. Similarly, it is much cheaper than high-end servers.
Hadoop runs the program on cluster computers. Similarly, Hadoop performs some core tasks to process the code which includes:
- To perform parallel computing Hadoop divides the data into the uniform size of blocks into files and directories. The block size can be 128M and 64M.
- After that, for further processing, Hadoop distributes the files across different cluster computers.
- HDFS monitors the processing of cluster computers.
- In case of hardware failure, The framework replicates the blocks of the data set to avoid corrupting the original data.
- Hadoop frameworks then check whether the code is successfully executed or not.
- It performs the sorting of data between the reduce and map stages.
- After the frameworks sort the data in proper order, Frameworks sends the data to the main computer.
Hadoop Architecture
Hadoop has an architecture for data storage. It distributes the data processing using MapReduce and HDFS techniques. Hadoop Architecture is also known as Master-Slave architecture. There are various nodes that perform a particular task.
- NameNode: It represents every file and directory. For storing the data we use these files and directory.
- DataNode: It helps you to communicate with the block or data sets. It also helps you to manage the state of the HDFS node.
- MasterNode: Using the MapReduce method, the MasterNode allows you to perform parallel processing of data.
- SlaveNode: In the Hadoop cluster, we connect various low-end systems to each other. These systems are known as the SlaveNode. These SlaveNodes perform complex calculations.
Features of Hadoop
- Big Data Analysis: Big Data is the large number of datasets that are collected from various industries. Therefore the data can be distributed and unstructured in nature. Hadoop cluster computing technique is best for analyzing the data in Big Data.
- Scalability: Hadoop clusters can easily add more cluster nodes into their cluster. However, the scaling process does not affect any modification to application logic.
- Fault Tolerance: Hadoop framework replicates the input data. In case any hardware failure occurs, the frameworks use the replicated data on another cluster node for further processing.
Pros and Cons of Hadoop
Pros
- It can store a large amount of data. For instance, the data size can be in gigabytes to petabytes.
- Hadoop clusters can easily add multiple cluster nodes into their cluster. This improves scalability.
- It uses multiple low-end systems to perform data processing instead of heavy servers. This reduces the cost of infrastructure.
- However, Hadoop performs parallel processing simultaneously between various nodes, thus increasing the computational power.
- It also gives independent tasks to every node.
Cons
- This framework is built to manage a large amount of data only. Therefore it is not effective for a small amount of data.
- Managing the cluster is a difficult process. Monitoring each node function is a lengthy process.
- The Hadoop cluster is not highly secured.
Spark
Apache Spark is an open-source data processing engine. Organizations use it to process a large number of data sets. Spark also distributes the data across multiple nodes as we have seen in the Hadoop ecosystem. But Spark performs the task faster than Hadoop. The main reason behind the performance of the Spark framework is that its uses RAM (Random Access Memory) instead of the file system.
Spark is the only framework that combines data and AI to perform data processing. Users can perform large-scale data processing and then run it on Machine learning and AI algorithms. The Spark Framework consists of five modules.
- Spark Core: Spark core is an execution engine schedules and dispatches the task to every node. It also monitors the input and output operations between the nodes.
- Spark SQL: This module collects the information related to structured data. In addition, it has the feature of optimizing structured data processing.
- Spark Streaming and Structured Streaming: Spark streaming is the process in which the data from different streaming sources is collected. After that, it distributes the data into micro-batches to perform continuous streaming. The framework uses Structured Streaming modules to simplify the program. It also reduces the latency.
- Machine Learning Library (MLlib): It includes various Machine learning algorithms, APIs, and tools. For instance, DataFrames is the primary API that provides uniformity between different programming languages.
- GraphX: GraphX is a computational engine that enables the modification and analysis of structured data.
Pros and Cons of Spark
Pros
- It uses RAM for the processing of data. Hence, It provides faster speed in computing.
- It is easy to use and user-friendly. Spark uses build-in APIs for operating large data sets.
- Sparks supports Machine Learning, graph algorithms, and Data Streaming.
- It is dynamic in nature. Therefore, you can easily develop parallel applications with Apache Spark.
- It Supports different programming languages like java, python, etc.
- Apache Spark has a low Latency data processing capability. Therefore, it can handle critical analytics tasks.
Cons
- It does not support an automatic optimization process.
- It uses RAM for data processing. Therefore, it does not have a file management system.
- This Framework is built to perform a large number of data sets. Therefore, we cannot process a small size of data in this framework.
- It is not suitable for multiple users.
Difference Between Hadoop and Spark
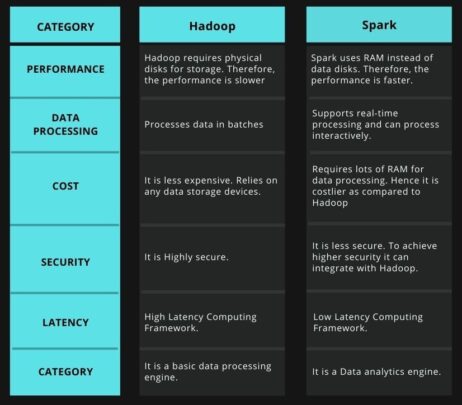
Conclusion
Apache Software Foundation has developed Spark and the Hadoop Framework. Both frameworks are open source. Apache has built it to perform big data computational tasks. Apache uses the Cluster computing technique, whereas Spark uses AI and Machine learning features. Each framework has its own modules and technologies to perform processes, manage, and analyze big data sets.
You may also like to read: Apache Kafka Use Cases. What is Apache Kafka?


