
In today's world, the term "Data" can have multiple meanings and ways to extract or interpret it. For this reason, Google Cloud Platform (GCP) has three major products in the field of data processing and warehousing. Dataproc, Dataflow and Dataprep provide tons of ETL solutions to its customers, catering to different needs.
Dataproc, Dataflow and Dataprep are three distinct parts of the new age of data processing tools in the cloud. They perform separate tasks yet are related to each other.
Dataproc is a Google Cloud product with Data Science/ML service for Spark and Hadoop. In comparison, Dataflow follows a batch and stream processing of data. It creates a new pipeline for data processing and resources produced or removed on-demand. Whereas Dataprep is UI-driven, scales on-demand and fully automated.
In this comparison of Dataproc, Dataflow and Dataprep blog, I will give you an idea of how these three data processing tools differ from one another.
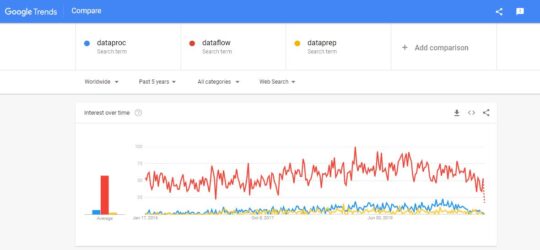
From the above Google Trends screenshot, we can check that Dataflow is way ahead of Dataproc and Dataprep in customer preferences.
Giving a brief history, Google published its research paper on MapReduce back in 2004. Since then, Hadoop has become a significant player in the world of Big Data.
Coming to 2014, Apache released Spark, which is open-source and a cluster-computing framework.
Spark has a robust module for working on the entire group of clusters with data parallelism. Soon, Apache Spark gained popularity and was seen as an alternative to Hadoop.
Many companies started using Spark and Hadoop in tandem, but this led to overheads and confusing configurations. This proved to be complicated and costly.
Even if you don't want to use a particular cluster in your big data, you'd still need to pay for it. According to GCP, you can migrate your entire deployment of Spark/Hadoop to fully-managed services. It mechanically creates clusters, manages your cluster in Dataflow.
It has a built-in reports system in place, and most importantly, it can also shut down or remove the cluster on-demand.
Features:
- With your existing MapReduce, you can operate on an immense amount of data each day without any overhead worries.
- With the in-built monitoring system, you can transfer your cluster data to your applications. You can get quick-reports from the system and also have the feature of storing data in Google's BigQuery.
- Quick launch and delete smaller clusters stored in blob storage, as and when required using Spark (Spark SQL, PySpark, Spark shell).
- Spark Machine Learning Libraries and Data Science to customize and run classification algorithms.
The primary data processing techniques like the ETL are left-out when optimizing your data. According to Google, Dataflow can manage and operate batch and stream processing of data.
The main objective of Dataflow is to simplify Big Data. The programming and execution frameworks are merged to achieve parallelization. No cluster data is kept idle in Dataflow. Instead, the cluster is continuously monitored and remodeled (according to the algorithm in use).
Dataflow allows Apache Beam tasks with all the in-built functionality. Also, to run on Google Cloud Platform, which can be sluggish for any other tool.
Features:
- ETL(Extract, transform, and load) data into multiple data warehouses at the same time.
- Dataflow is considered as MapReduce replacement to handle large number of parallelization tasks.
It can scan real-time, user, management, financial, or retail sales data. - Processes immense amounts of data for research and predictions with data science techniques. Such as genomics, weather, and financial data.
Dataprep was created to solve three major problems, i.e., lack of data visualization, redundant data, and slow processing. Dataprep allows users to explore data visually by transforming the file into CSV, JSON, or in a graphical table format.
Dataprep can easily handle clusters and datasets in the size of TBs. Dataprep is used only as a medium of processing data for further use, such as in BigQuery.
Sometimes, with the scale of data usage, there occurs a problem with security. Hence Google Cloud provides Dataprep with its own Identity and Access Management.
Features:
- One can prepare the dataset by removing the redundant data with the help of ML and Data Science.
- You can transform raw data into a visual representation, such as graphs and tables.
- One can keep the security in check with reduced exposure to the dataset.
Also Discover: How Will Data Visualization Shape in the Future?
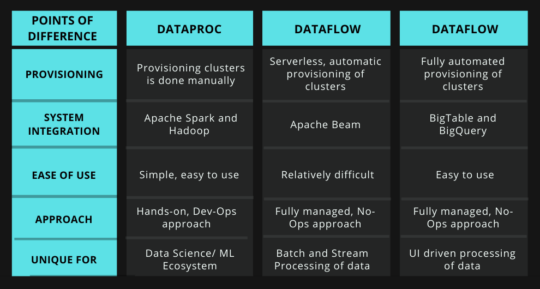
Dataproc supports manual provision to clusters, whereas; Dataflow supports automatic provision to clusters. Dataprep helps to prepare and clean the data for future use.
If systems are Hadoop dependent, then it is wise to choose Dataproc over Dataflow or Dataprep. Dataproc was created as an extension service for Hadoop.
If one prefers a hands-on Dev-ops approach, then choose Dataproc. In comparison, if you prefer a serverless approach, then select Dataflow. Dataprep, on the other hand, is UI-driven.
As we have already seen before, many prefer Dataflow over Dataproc and Dataprep. According to G2 user reviews, many say that Dataproc is easier to use compare to Dataflow. In contrast, Dataprep is only seen as a data processing tool.
Real-time data collection with Hadoop and Spark integration feature is more prominent in Dataproc. The data lake, data collection, cleaning, cloud, and workload processing are highly rated for the Dataflow. Visual analytics and processing data with the help of Dataprep is seen as its plus-point.
In terms of portability, Data flow merges programming & execution models. This way, it achieves data parallelization and is more portable than Dataproc and Dataprep.
While comparing Dataproc, Dataflow, and Dataprep, there are a few similarities that are:
- It is obvious to state that all three are the products of Google Cloud.
- All the pricing comes in the same bracket, i.e., new customers get $300 in free credits on Dataproc, Dataflow or Dataprep in the first 90 days of their trial.
- Support for all three products is on par with each other.
- All are categorized as Big Data processing and distribution.
Dataproc vs Dataflow vs Dataprep: Conclusion
In this blog, we differentiated between GCP Dataproc, Dataflow, and Dataprep. All are equally at par with each other in data processing, cleaning, ETL and distribution.
They cater to individual needs, i.e. if you have dependencies on Hadoop/Apache services, then it is clear that one should choose Dataproc.
Even if you don't have Hadoop/Apache dependencies but would like to take a manual approach to big data processing, you can also choose Dataproc.
But if one wants to take advantage of Google's premium services of Cloud data processing and distribution and at the same time, one doesn't want to get into the nitty-gritty aspect of it, then go for Dataflow.
If you are only looking to find any anomalies or redundancy in the data, choose Dataprep. It is also integrated with other premium Google Cloud products.
One needs to understand his/her own needs to reap these three Google Cloud products' benefits. All are meant to meet specific requirements and are easy to use for businesses of all sizes.
You may also like to read: Big Data Trends for 2020 You Need to Know


