
Speech synthesis basically translates written information into aural information using a machine-generated voice.
It is best for learning foreign languages, for visually impaired people wherein the contents on the screen can be read out loud for them.
Some of the prominent examples of speech synthesizers are Alexa, Cortana, and Google Home.
Below discussed are some of the tools that can be used for speech synthesis.
Complete List of Best Speech Synthesis Software
Google cloud’s Text-to-Speech allows developers to be able to synthesize natural sounds into more than 100+ voices.
It mostly involves DeepMind’s WaveNet research and Google’s neural networks for delivering speech outputs.
Key Features:
- Voice and Language Selection: You can avail of a wide variety of 220+ voices and 40+ languages.
- Pitch Tuning: Users can increase or decrease their selected voice pitch up to 20 semitones more or even less than the default.
- Audio Format Flexibility: Get the desired outputs in formats like mp3, Linear16, and Ogg Opus.
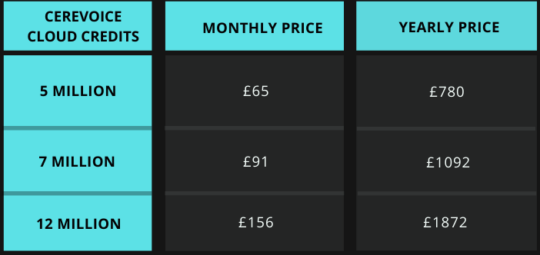
Price:

CereVoice is an online voice cloning web-based tool developed by CereProc.
Users can use it from their own computers without the need of any supportive equipment or studio type environment.
Users have to read the specially designed script.
Data collected through this script is further used to build a Windows SAPI5 TTS or MacOS version of your own voice.
It is available in English, Spanish, French, Swedish, Italian, and Romanian.
Key Features:
- Output Capacity: Stereo and 3D audio output capability are available for users.
- Integration: The speech synthesis functions work well across all the different types of applications, be it mobile, web, or server-based.
- Free Distribution: You won't be burdened with any additional fees for distributing the audio generated through this software
Price:
Also Read: Is Self Thinking AI Possible and What can be its implications?
eSpeak is an open-source software speech synthesizer.
Multiple languages are provided to users in smaller sizes as these tools use a formant synthesis method.
The voice output generated through eSpeak is clear and can be used at higher speeds.
Key Features:
- Output: Users through eSpeak will receive their outputs in the WAV file format.
- Alteration: Multiple voices that can be altered are made available for users by eSpeak.
- Compact Size: The data and the program files amount to only 2Mbytes.
Price: It is open-source software, thus free.
Voicery is an advanced neural speech synthesis engine.
Users are provided a customizable solution of text-to-speech based on the interactions done with them.
Business requirements of text-to-speech models for users are duly selected while working directly with the Voicery team.
If users want to deploy their voices on any platform, Voicery allows them to do so by recording their voices through script readings, studio readings, and audio processing.
Key Features:
- Touch of AI and Deep Learning: Users can add accent as well as emotions in their voices with the help of AI and deep learning technologies.
- Deployments: Easy deployment of this tool can be done on cloud, on-premise, or even offline.
- Audio Adjustments: Speech synthesis markup language helps in making adjustments like pauses, audio formatting, etc.
Price:
- For Starters: users are charged $ 0.001 per character with benefits like access to voice library up to 100 requests per second.
- For Enterprise: For enterprise benefits like Bulk usage discounts, Custom exclusive voices, and unlimited requests, users need to contact the sales team.
Overdub is great for making short editorial corrections.
Users can put together some placeholder audios, and real sounds can replace the same audios.
Once users have set up an Overdub voice by recording minutes of audio, they will have to open a Descript project.
Users will then select the Overdub voice from the speaker label list and type or either paste text.
While typing descript will automatically generate audio in your voice.
If users wrote their script in other tools, they can copy and paste it on Overdub, and users will be ready to go.
Key Features:
- Easy to use: Overdub’s integration with Descript makes it easy to create audio like typing.
- Sharing: Users can easily share their Overdub Voice with other platforms for generating audio.
- Blends right in: If there are some changes to be done between some sentences of real recordings, Overdub is capable of matching the tonal characteristics in a sentence also and in the recording also.
Price:
- Pro Version: $30 per user per month is charged to users while opting for monthly plans and $24 per user per month for annual packs with benefits of Overdub, Audiograms pro, and 30hrs of transcription per month.
- Enterprise version: Need to contact the sales team.
MaryTTS (Modular Architecture for Research in Synthesis Text-to-Speech) is an open-source platform.
It is a multilingual Text-to-speech synthesis platform that is written in Java.
Users with the help of its toolkits will find it easy in adding supportive languages to the MaryTTS platform.
MaryTTS is licensed under LGPL.
This thus allows users to make modifications and use it for commercial purposes also.
Key Features:
- Preprocessing: Methods like tokenizer, abbreviation expansions as well as numeral expansions of the text allows separations of concerns from texts. Moreover, if any SABLE annotation is given in the inputted texts, XML structure assists in translating the same.
- Multi-threaded: Multiple requests can be run in parallel by the server as each request is processed in its own threads.
- Flexible: Both java modules and external modules (programs from stdin and writing to stdout) can easily be integrated into the system.
Price:
Being an open-source platform it is thus free to use.
Acapela virtual speaker allows users to create high-quality voice recordings.
It does so with the help of virtual recording studios installed on the user's PC.
Key Features:
- Adjustable Voice Settings: For better outputs, users have the ability to make certain adjustments like speaking rate, Voice tone, and Volume, and pause length for punctuation.
- Manual Mode: Users for desired outputs can themselves do the editing on their file like opening a text file, listening to it, making adjustments to its properties, and creating perfect recordings.
- Output Formats: Users can receive outputs in formats lie MP3, vox, A-Law, PCM.
Price:
Its pricing is based on pre-paid packages of speech hours or time credits.
Application is free, but users have to pay for the amount of audio needed to generate.
The first pre-paid package amounts to €1500 for a 5-hour time limit.
Festival offers text-to-speech through several APIs.
These APIs are shell level, scheme command interpreter, a C++ library, and an Emacs interface.
The Festival is written in C++.
It uses the Edinburgh Speech Tools Library for architectural purposes, and for control objectives, it uses a Schema-based command interpreter.
- Advanced Architecture: By deleting the old codes meant for compatibility reasons, lower-level system interfaces will now be able to register new features. Thus changing the focus for registering new features from one particular function to one directory.
- General Statistical Model: Introduction of models like WFST, CART with a generalized Viterbi function has made adding complex statistical models easy without opting for new C++.
- JSAPI and JSML Support: Java Speech API is based on event-handling.JSML elements provide speech synthesizers with detailed information on speaking texts in a naturalized fashion. With the presence of both JSAPI and JSML events and information derived from speech, synthesizers help improve the outputs.
Price:
Under the X11-type license, it can be freely used.
NaturalReader is downloadable text-to-speech desktop software.
It is mainly used for personal purposes.
Texts such as Microsoft Word files, webpages, PDF files, and E-mails will be easily readable to a user with natural sounding voices.
NaturalReader provides the users with other platform application too like:
- Online: Listening to notes, Office documents, or printed books from the computer or mobile devices.
- Commercial: Generated audio files can be further used in YouTube Videos, e-learning modules, public announcements, etc.
- WebReader: Make webpages talk to you by installing this text-to-speech widget on your websites
Key Features:
- Multiple Document Format: Users can generate voices by presenting the text in formats like PDF, Docx, and text documents.
- OCR with Printed Documents: If users want to listen to their printed text, the OCR function of these tools helps them to do so.
- Miniboard: Simply read texts directly on the page.
Price:
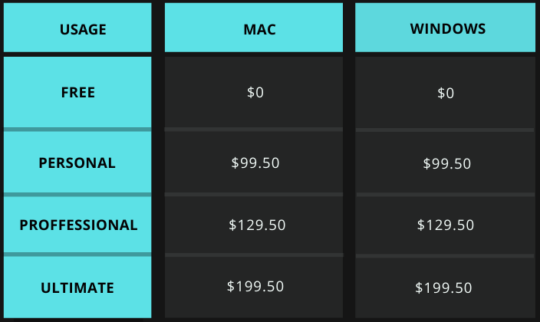
All prices are one-time payments.
TextAloud 4 is developed by NextUp technologies.
This tool makes it quite easy for any user to convert their documents, PDF, and more into natural speech.
- Integrations: Users on installing TextAloud 4 will find a floating toolbar that will allow them to read any selected text from the window. This toolbar can be found as a built-in extension for Chrome and Microsoft Word.
- Proofreading: Helps in making efficient and accurate communication. With TextAloud, proofread your email messages before sending them.Proofreading will read out your words in messages back to you and will help improve communication and catch errors.
- Saving Audio Files: Users can save their audio files and read it anywhere in the near future with TextAloud's help that saves your daily readings into audio files.
A single-user license is priced at $34.95
iSpeech TTS is an online text-to-speech service.
iSpeech text when integrated with website voice reader makes sure that the information is properly understood by the visitor on users' websites.
Key Features:
- Speed: Users can choose between three reading speed i.e., slow, regular, and fast. If users want to produce their output speech in male or female voice they can do so with the help of this tool.
- Formats supported: Users won’t find any difficulty in playing the downloaded audio as the same is supported in multiple formats like wav, mp3, ogg, wma, aiff, alaw, ulaw, vox and mp4.
- Language library: Go for the High-quality natural sounds that can be accessed in 27 languages with different accents.
Price:
It is a free online Text-to-speech service of iSpeech.
Zabaware text-to-speech reader is an application using speech synthesizers to read the documents.
Users can find an ear icon displayed by default signifying the installation of Zabaware text-to-speech reader.
This platform is compatible with any SAPI 4 or SAPI 5 compliant speech synthesizer.
Key Features:
- Speed Reading: Users can quickly finish reading multiple documents by just simply setting the speed high for this tool.
- Rapid Serial Visual Presentation: If users find it stressing going through each line and word this tool reduces the eye movement using Rapid serial visual presentation. The program also adds supplementary fast spoken speech for better understanding.
- Visual impaired friendly: Highlight desired text with the mouse and hit CTRL+C to read it aloud.
Price:
Available for free with generic voices.
Conclusion
To conclude, there are many more TTS software available for multiple types of reading needs.
However, before opting for any of the above-mentioned Speech Synthesis Software, users have to evaluate their business needs and set the frameworks for the same in order to achieve the best results.
Also Read:
Here is everything to know about Affective Computing and its Applications
Understanding Neural Network Architectures for Machine Learning
6 Best VDI Solution Providers for Businesses to Invest In


