
In this topic, we will learn about Data Lake and Data Mesh. As modern businesses grapple with ever-increasing volumes of enterprise data, many are rethinking their data management strategies to figure out the best way to deliver business insights and analytics at scale.
With this goal in mind, most businesses seek ways to examine data without spending time and money moving or changing it. Therefore, The popularity of data lake and data mesh architectures is growing.
Data Lake and Data Mesh: Which is better?
What is Data Lake?
A data lake is a centralized repository that can hold both organized and unstructured data at any scale. In other words, you can use dashboards and visualization to guide better decisions and you can run various sorts of analytics—from big data processing, real-time analytics, and machine learning—without requiring to first organize data.
Almost the majority of data lakes are created on a cluster of low-cost, scalable commodity hardware. Similarly, this allows data to be dumped into the lake and later extracted without having to worry about storage space. On-premises or in the cloud, the clusters could exist.
Need for Data Lake
Organizations that are able to extract business value from their data will outperform their competitors. According to an Aberdeen study, organizations that implemented a Data Lake outperformed similar enterprises by 9% in organic revenue growth. These leaders were able to perform new forms of analytics, such as machine learning, using new data sources in the data lake, such as log files, data from click-streams, social media, and internet-connected gadgets.
Benefits of Data Lake
The schema-on-read principle regulates the function of a data lake. This means that data does not need to be fitted into a predefined schema before being stored. It enables data to be saved in its original form in any format. Similarly, Data lakes allow data scientists to access, prepare, and analyze data more quickly and accurately.
Data Lake Architecture
It's vital to understand that a data lake has two parts: storage and execution. On-premises or in the cloud, both storage and computing can be used. Organizations can choose to stay on-premises, migrate their entire architecture to the cloud, use several clouds, or combine these options. In addition, there are various good solutions depending on an organization's needs. Here are some of them.
Data Lakes with Hadoop integration
A Hadoop cluster of distributed servers solves the problem of huge data storage. Hadoop's storage layer, HDFS, is at its core, storing and replicating data across several servers. The resource management YARN (Yet Another Resource Negotiator) manages how to allocate resources on each node. Hadoop uses the MapReduce programming model to split data into smaller subsets and analyze it on its cluster of machines.
Hive, Pig, Flume, Sqoop, and Kafka are some of the supplemental technologies that help with data collection, preparation, and extraction in the Hadoop ecosystem. Enterprise platforms such as Cloudera and HortonWorks can help set up Hadoop data lakes both on-premises and in the cloud.
Advantages
- Because it is open-source, it is less expensive.
- Scalability is simple.
- There are numerous ETL technologies available for Hadoop integration.
- A greater level of acquaintance among technologists
- Computation is sped up by data locality.
Data Lakes with AWS integration
Data Lakes with AWS integration
The solution's storage function is provided by Amazon Simple Storage Service (Amazon S3), which is at the core of the solution. Data ingestion solutions such as Kinesis Streams, Kinesis Firehose, Snowball, and Direct Connect allow users to send large amounts of data into S3.
A database migration service is also available to assist with the migration of existing on-premises data to the cloud.
Advantages
- Strict security and compliance requirements
- Flexibility in selecting items depending on specific criteria
- A comprehensive and feature-rich product suite is available.
- We can separate Compute and storage to allow each to scale as needed.
Data Lakes with Azure integration
Microsoft Azure is a data lake service. It has a storage and analytics layer, with Azure Data Lake Store (ADLS) functioning as the storage layer and Azure Data Lake Analytics and HDInsight functioning as the analytics layer. Similarly, to develop ADLS Azure uses the HDFS standard, which has an unlimited storage capacity.
It has the capacity to store trillions of files, each of which is greater than one petabyte. HDInsight is a data lake analytics solution that is hosted in the cloud. It's built on top of Hadoop YARN and lets you access data with Spark, Hive, Kafka, and Storm. Because of its interaction with Azure Active Directory, it provides enterprise-level security.
Advantages
- Strong analytic services with a wide range of capabilities.
- Many big data experts are familiar with Hadoop and its technologies, making experienced staff relatively easy to come by.
- It is straightforward to handle both storage and computing in the cloud.
- It's simple to move from an existing Hadoop cluster.
- Integration with Active Directory eliminates the need for a separate security management effort.
Data Mesh
Data mesh is a new technique to design current data architectures that take into account both organization and data-centric components, data management, governance, and so on. According to the approach, data should be easily available and networked across the entire enterprise.
Data mesh is a relatively newer term that is still in its early stages of progress, similar to how microservices are a set of principles for designing modern software architectures.
While microservices include frameworks like Spring Boot and Micronaut, as well as specified procedures, books, and a variety of additional infrastructure, data mesh has a dearth of training resources, tutorials, and instructions.
While microservices include frameworks like Spring Boot and Micronaut, as well as specified procedures, books, and a variety of additional infrastructure, data mesh has a dearth of training resources, tutorials, and instructions.
Principles of Data Mesh
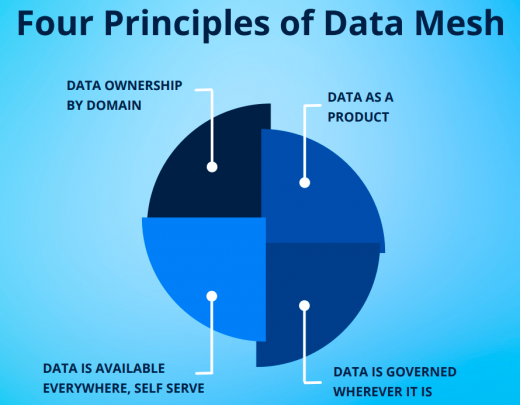
To comprehend how data mesh works, we must first comprehend its four fundamental concepts. Each of the four principles is technology agnostic. Therefore, data mesh is adaptable in the sense that it allows you to add more computing as required, but it is also adaptable in the sense that it can accommodate changes as a business expands, changes, and grows, as well as the things that people want out of data. The following are the principles of data mesh.
Data Ownership by Domain
Data mesh is divided down around a specific business domain, similar to how microservices each possess a specific business function. There is no central data bureau, no data team, no analytics team, etc., so access to that data is decentralized.
There is no central data bureau, no data team, no analytics team, etc., so access to that data is decentralized. Rather, that data has a home, most likely with its functionality, i.e. the microservices that generate it. At that moment, you have access to the data.
Data as a Product
Each team that publishes data considers it a product in the data mesh. Data is owned by a team in the same way that the set of services that implement the slice of the business that they support is owned by a team. That group must apply product thinking to the data: They are completely in charge of the data, including its quality, representation, and cohesion.
Data is Available Everywhere, Self-Serve
In the data mesh, all data is self-serve and accessible from anywhere in the corporation. Although governance is still an issue, data products have been produced and are accessible from anywhere.
If you are creating a sales prediction for Japan, for example, you should be able to get all of the data you need in a matter of minutes. You would be able to swiftly get all the information you require from all the sources and enter it into a database or reporting system you control.
Data is Governed Wherever it is
As previously said, governance is still an issue in data mesh, but it is best addressed at the point where data is created and produced.
There is no such thing as a flawless or static data architecture; things always change and grow. However, you can ring fence this with governance, allowing you to trust and explore data in the mesh more rapidly, and believe—subject to governance restraints—that you can use the data you find.
Data Mesh Architecture
Data architectures are frequently lacking in rigor, evolving in an ad hoc manner with little discipline and organization.
Similarly, using data Mesh can transform a point-to-point design into a more consistent and manageable system—a kind of data central nervous system.
Because it is a mesh, the nervous system is an excellent metaphor for data mesh. You will notice a tangle of unconnected small products when you look inside a brain. Similarly, with data mesh, an occurrence in one part of your company can instantly trigger an event in another, because they are all interconnected in an analytics way.
Benefits of Data Mesh
To tackle a variety of challenges organizations can use the Data mesh tool. On a smaller scale, it addresses many of the challenges that data pipelines face, such as how they can become fragile and problematic over time by developing their own webs and point-to-point systems.
It also handles wider organizational difficulties, such as internal divisions within a company disagreeing on key business facts. You are less likely to have duplicate facts in a data mesh. For instance, A data mesh can help a system gain much-needed order in each of these scenarios, resulting in a more mature, maintainable, and evolvable data architecture. Other than this there are also several benefits of Data Mesh.
- Scalability and Business Agility
- Access to information more quickly and with greater accuracy.
- Flexibility and autonomy.
- Data Security and Platform Connectivity
- End-to-end compliance requires robust data governance.
- Transparency Through Cross-Functional Teams
- Get More Out of Distributed Data with Data Mesh in Action
IT and DevOps
Data mesh provides data analytics and software teams with a new development approach. In addition, it decreases data latency by giving users immediate access to query data from nearby regions with no access restrictions.
Sales and Marketing
The distributed data allows sales and marketing teams to create more targeted campaigns, improve lead scoring accuracy, and forecast customer lifetime values (CLV), churn, and other important performance metrics by curating a 360-degree view of consumer behaviors and profiles from various systems and platforms.
AI and Machine Learning Training
Without needing to combine data in a central area, Data Mesh allows development and intelligence teams to generate virtual data warehouses and data catalogs from many sources to feed machine learning (ML) and artificial intelligence (AI) models to aid learning.
Loss Prevention
In the financial sector, implementing a data mesh reduces operational costs and risks while increasing time-to-insight. Fraudulent behavior modeling is conducted using distributed data analytics to detect and prevent fraud in real time. It enables multinational financial institutions to evaluate data locally – inside any given country or region – in order to detect fraud concerns without having to replicate and transport data sets to a central database.
Global Business
With end-to-end data sovereignty and data residency compliance, a decentralized data platform makes it simple to comply with global data governance rules and provide global analytics across various locations.
Difference between Data Lake and Data Mesh
Here are some key differences between data mesh and data lakes.
Operational Use Case
For both analytical and operational use cases, each business domain retains complete control over all aspects of its data products in Data Mesh.
Data Lake does not support Operational use case.
Data Management Design
A Data mesh is a design for federated data management.
A data lake is a design for centralized data management.
Dependency
Data mesh allows data consumers to self-serve. Thanks to Data Mesh, authorized data consumers may easily identify, access, and exchange data products, which protects them from the data complexities inherent in underlying systems.
Data lakes rely on data engineers, or data scientists, to prepare and furnish the required data, which is often a time-consuming, repetitive, and error-prone process that delays insights.
Data Governance
Federated data governance is supported by data mesh. Business domains can design and supply their own data products using data mesh while complying with centralized data governance standards. As a result, data mesh improves agility and speed.
Whereas in Data lakes necessitate centralized data governance, which can be difficult to implement when dealing with data that comes from several sources and is stored in various formats.
Data Platform
Data Mesh has a decentralized data platform.
Whereas, Data Lake has a centralized platform.
Approach
Data Mesh offers a more organizational approach than a technical approach. Technical support supports the distributed approach.
Data Lake supports both technical and organizational approaches.
How to choose the right option?
Data lakes and data meshes may and should coexist; they are not mutually exclusive. For instance, many businesses already have the cloud infrastructure in place to pursue a data lake strategy. However, organizations should search for a platform that allows them to run queries without having to relocate data.
Others save their information in a variety of databases, both on-premises and in the cloud. A cloud data lake could be one of those endpoints. In this situation, a mesh architecture could be ideal.
However, to make data discoverable and adjustable, there should ideally be a standards organization, or contract, that exists within a data mesh architecture between data producers and consumers.
Conclusion
Because data lakes and data mesh architectures adopt distinct approaches (e.g., data integration), these two strategies should be considered complementary rather than competing. Data mesh and data democratization are synonymous; you can't have a decentralized data architecture if there are gatekeepers controlling access. Similarly, this will be an important issue to follow in the future years as more organizations create novel techniques to democratize data access.
Recommended For You:
Exploring Diverse Data Mining Techniques for Insightful Analysis


