
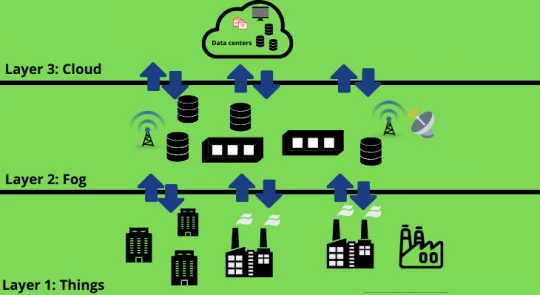
Extending cloud services to edge devices is fog computing.
The scope of fog computing starts from the outer edges where the data is collected to where it will be stored eventually.
Fog nodes play a vital role in the overall working of fog computing as they collect the data from multiple sources for further processing.
Fog nodes are distributed as well as deployed across the network. Data is analyzed with the help of these nodes.
These nodes act as decentralized local access, thus reducing the dependency on the cloud platform for analyzing the collected data.
The working process of fog computing can be further explained as follows:
-
- The automation controller reads the signals sent from IoT devices.
- The control system uses protocol gateways for transmitting the collected data.
- This data is converted into formats that could be easily understood by HTTP or MQTT.
- This data is collected by fog nodes that analyze the data and convert the data into sets before forwarding them to clouds.
There are two types of nodes present in these layers; these are physical and virtual nodes.
Nodes are initially responsible for the collection of data at multiple locations.
Nodes are equipped with sensor technology, which helps them in collecting the data from their surroundings.
The data thus collected is sent for processing with the help of gateways.
This layer is usually involved with the tasks of monitoring various nodes.
It involves monitoring the time of work a node is taking, the temperature, and the battery life of the device.
This layer is involved in the analysis part.
The main job of this layer is to bring out meaningful data from the information collected from multiple sources.
Data that is collected by nodes is thoroughly checked for errors and impurities.
This layer makes sure that the data is thoroughly checked before being used for other purposes.
Mainly used for storing the data before it is being forwarded to the cloud.
Data is stored with the help of virtual storage.
As the name of the layer suggests, this layer is entirely for the security of the data.
This layer takes care of the privacy of the data, which includes encryption and decryption of data.
The primary function of this layer is to upload the data to the cloud for permanent storage.
The data is not uploaded completely; preferably only a portion of it is uploaded for efficiency purposes.
To ensure that the process is efficiently completed, the use of lightweight communication protocols is used.
Also Read: Cloud Computing vs. Virtualization: Difference Explained
Because of the connectivity of the fog nodes with efficient and smart end devices, the analysis and generation of data by these devices are quicker.
This results in lower latency of data.
Fog computing is quite a heterogeneous infrastructure, as it can collect data from multiple sources.
Being a virtualized platform providing end-user storage and other services like networking, it acts as a bridge between end devices and traditional cloud computing centers.
Many fog computing applications have to communicate with mobile devices.
This makes them conducive to mobility techniques like LISP (Locator/ID Separation Protocol).
The main task of LISP is to decouple the location and identity.
Being adaptive in nature at the cluster level, it is able to support the majority of functions like elastic compute, data -load changes, and network variations.
Although fog computing is widely used in wired environments.
But the wireless sensors spread on vast areas associated with IoT devices demand different requirements related to analytics.
For this also, fog computing is suitable for wireless IoT access networks.
Working Architecture of Fog Computing
You May Also Like To Read:


