
This article will go through the difference between mirroring and replication. The terms "mirroring" and "replication" have more to do with copying data in a DBMS. Replication involves copying data and database objects from one database to another, whereas mirroring refers to moving a database to another place.
Both mirroring and replication have benefits and improve the database's performance and availability.
Understanding the difference between Mirroring and Replication
What is Mirroring?
Data mirroring is known to replace the content of files that have been copied into or updated within USB devices. Once mirror copies have been created, they can be kept in a network share that requires a password. To conserve space on local machines, it is better to store this sharing folder remotely.
Only the administrator or trusted users can securely access and analyze the database. You can use data mirroring software to set up policies so that data mirroring occurs either anytime any file activity is performed on a USB or only when particular file actions are carried out. It is also possible to record information about the file operation, such as the file name, users, endpoints, and devices involved.
When done appropriately, data mirroring, which needs a lot of bandwidth and disc space, is an efficient approach to protect business data that has been moved outside of the network via detachable devices.
Benefits of Data Mirroring
Following are the benefits of data mirroring.
Recognize compromised data to implement remediation procedures.
The data mirroring software ensures that the sharing folder can still be used if and when circumstances occur when information is lost due to data theft or any other human or hardware-related error after being transmitted.
Reduce downtime by restoring vital information.
Data needed for essential tasks or data accessed by many employees must be kept intact. It is equally crucial that authorized personnel constantly have access to the data so that they can use it as needed.
The files in highly classified vaults that are frequently accessed is directly transferred from share.
The administrator would have to give users high-level access each time they would need a specific file if it were regularly needed yet happened to be indexed in a top-security repository with many other secret documents.
What is Data Replication?
Data replication is the process of creating numerous identical copies of data and storing them at various locations in order to improve accessibility across a network, provide fault tolerance, and serve as a backup copy.
Data replication is similar to data mirroring in that it can be used on both servers and individual computers. The same system, on-site and off-site servers, and cloud-based hosts can store data duplicates.
Asynchronous data replication, in which replication begins only when the database receives the Commit statement, is an alternative to synchronous data replication, which replicates any changes made to the original data.
Benefits of Data Replication
Following are the benefits of data replication.
Increase data accessibility
The data can still be accessed from another site or node if a particular machine has a technical issue because of malware or a defective hardware element. By storing data at many nodes around the network, data replication improves the resilience and dependability of systems.
Improves the speed of accessing the data
When accessing data from one nation to another, consumers may encounter some latency in firms with numerous branch offices dispersed throughout the globe. Users benefit from quicker data access and query execution times when replicas are placed on local servers.
Improve server efficiency
By spreading out the workload among additional nodes in the distributed system, database replication efficiently lightens the stress on the primary server and enhances network performance. IT managers can reserve the primary server for writing tasks that require more processing power by sending all read operations to a replica database.
Execute disaster recovery
Businesses are frequently vulnerable to data loss as a result of a data breach or hardware issue. The important data of the staff and client information may be compromised during such a tragedy. By keeping reliable backups at regularly inspected places, data replication makes it easier to retrieve data that has been lost or corrupted and helps to improve data protection.
Working of data replication
The back end of modern applications uses a distributed database, where data is stored and processed across a cluster of systems rather than depending solely on one machine.
Assume for the moment that a user of an application wants to add some data to the database. This data is divided into several pieces, each of which is kept on a different node throughout the distributed system. When a user wishes to obtain or read the data, the database technology also gathers and consolidates the many fragments.
With the use of data replication technology, read and write operations can be sped up throughout the network by storing several pieces at each node.
Tools for data replication make sure that in the event of a distributed system failure, entire data can still be consolidated from other nodes.
Types of Data Replication
There are various types of replication used by enterprises today, depending on the data replication methods used. Here are the different types of data replication.
Full table replication
The term "full table replication" denotes the replication of all data. This covers data that is copied from the source to the destination, both fresh and modified data. Since this replication method requires a lot of computing power and network bandwidth, expenses are typically higher.
Full table replication can be helpful when it comes to recovering hard-deleted data and data that lacks replication keys.
Transactional replication
The subscriber database receives updates anytime data is modified after the data replication software creates entire first copies of data from origin to destination. Fewer rows are replicated when data is modified, making this a more efficient replication method. Server-to-server setups are frequently seen to use transactional replication.
Snapshot replication
Data is copied exactly as it appears at any given time in snapshot replication. Data modifications are not taken into account during snapshot replication. When there are few changes to the data, this technique of replication is utilized.
Merge replication
Server-to-client systems frequently use merge replication, which enables both the publisher and subscriber to make dynamic modifications to data. The intricacy of employing this strategy is increased by the fact that data from two or more databases are joined to create a single database.
Key-based incremental replication
Only data that has changed since the last update is copied using this method. Keys can be thought of as components found in databases that cause data replication.
The disadvantage of this replication method is that since the key value is also erased when a record is deleted, it cannot be used to recover data that has been permanently deleted.
Data Replication Scheme
A suitable replication technique can be used to perform data replication in DBMS (distribution servers). Three data replication schemes are widely adopted.
Full data replication
When a distributed system has full replication, the entire database is replicated at each site. This plan maximizes data availability and redundancy over a broad area network.
Because any local server can provide the results, full replication helps global queries to run more quickly.
Full replication has the drawback of having a generally slower update process.
Partial data replication
Depending on the value of the data at each site, partial replication happens when only a subset of the database is duplicated. There can be one copy or as many copies as there are nodes in the distributed system.
This technique of replication in an enterprise setting, where a portion of the database is kept on personal computers and frequently synchronized with the main server, might be helpful for sales and marketing team members.
No replication
On each side of the distributed system, there is only one fragment in this manner of replication. Although the ease of data recovery can be linked to the absence of replication, the fact that several users can access the same server can negatively affect how quickly queries are executed. Lack of data replication in DBMS results in low data availability when compared to other replication strategies.
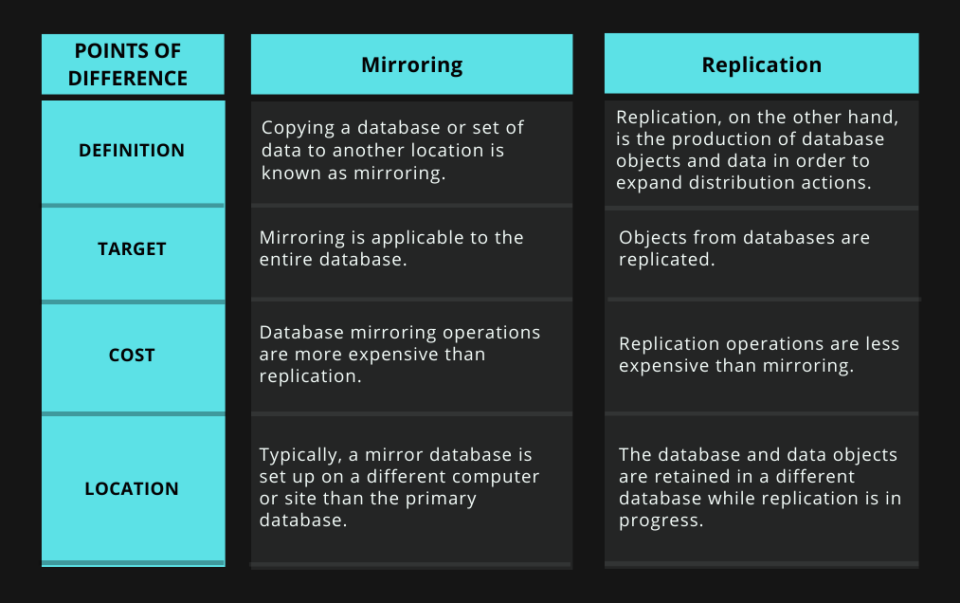
Difference Between Mirroring and Replication
The key distinctions between replication and mirroring are listed below.
Conclusion
The techniques of mirroring and replication aid in enhancing the data's availability, dependability, and performance. However, replication involves duplicating data and database objects like tables, stored procedures, user-defined functions, and materialized views, while mirroring requires redundant copies of a database.
You may also like to read: 7 Data Replication Strategies that are best for your business.


