
Data masking is one of the most prominent techniques used to protect sensitive information while continuing to let organizations work with realistic data. Globally, data breaches expose sensitive information and amount to huge losses for so many businesses in millions every year. For example, sources indicate that in 2021, the average cost for a data breach was about USD 4.24 million, which increased to USD 4.35 million in 2022. Therefore, protection of data has become the most paramount task for many organizations. That is why data masking architecture has emerged as one of the most vital techniques helping many businesses protect their sensitive data.
What is Data Masking?
Data masking or obfuscation is the process of transforming sensitive data into a non-sensitive version, so that it can be used for several purposes without hampering the original one. Data masking is the substitution of actual data with changed content such as changes in numbers and characters. It generates an alternative representation of source data that is irreversibly non-identifiable.
Data masking tools secures personally identifiable information (PII), financial, and health record data so that it is not accessed by the unwanted parties but remains that data useful for the testing processes. Of all the data types compromised, PII is the costliest among them. There are several types of data that you can protect using masking, but common data types that are ripe for data masking include:
- PII: Personally Identifiable Information
- PHI: Personal Health Information
- PCI-DSS: Payment Card Information
- ITAR: Intellectual property
Types of Data Masking:
There are many types of data masking types. Out of which static and on-the-fly data masking are common.
- Static Data Masking (SDM): SDM is designed to create a masked copy of live data, which can be used for non-production purposes. The method generally involves the data's sensitive points, assignment of masking rules, and finally, the line data which is produced later to be used freely with no limitations. SDM works best in scenarios involving infrequent or one-time masking, following which the data can be used in many environments.
- Dynamic Data Masking (DDM): It is the application of the masking rules in real-time on access to the data. It tries to protect sensitive information without changing the actual dataset. DDM intercepts queries made to the database and dynamically applies the masking rules, hence giving the masked view to the user and keeping the original data intact. It works in environments (especially production databases) where there is frequent access and updating of data.
- Deterministic Data Masking: Data masking is said to be deterministically set when the same original data value is kept in all cases as a masked value. One benefit of this approach is the consistency across different datasets that forms the quality basis of test processes. For example, if the name "Alice" appears more than once in different tables, the determined masking will go on replacing the occurrences with the same masked value "Eve."
- On-the-Fly Data Mask: Real-time data masking refers to data masking that is executed on the fly, for instance, when data is transferred from one environment to another like from a production environment to a test environment. This would be perfect in an environment with dynamism where time is not supposed to be wasted. The data would have been masked before being passed into the target environment, thus sheltering the sensitive information in the flow.
- Statistical Data Obfuscation: Obfuscation refers to slightly modifying data in a way that retains its statistical properties but washes off the actual data completely. The common uses would be in the hiding of sensitive information within the data analytics or research for the effective analysis process. For instance, statistical obfuscation techniques can be applied by a healthcare provider in hiding patient data but still retaining overall distribution characteristics of health metrics.
- Pseudonymization: Pseudonymization is the substitution of sensitive data with pseudonyms whereby reversible operations can take place by authorized users. This would apply in a case where the data needs to be reversible for authorized users. For example, a research organization could pseudonymize patient data to protect privacy, allowing re-identification of those individuals if necessary.
- Redaction: Redaction involves masking specific parts of a data field while leaving other parts visible. This technique is used for documents and text data. For example, a legal firm might redact sensitive information in documents shared with external parties.
Data Masking Architecture:
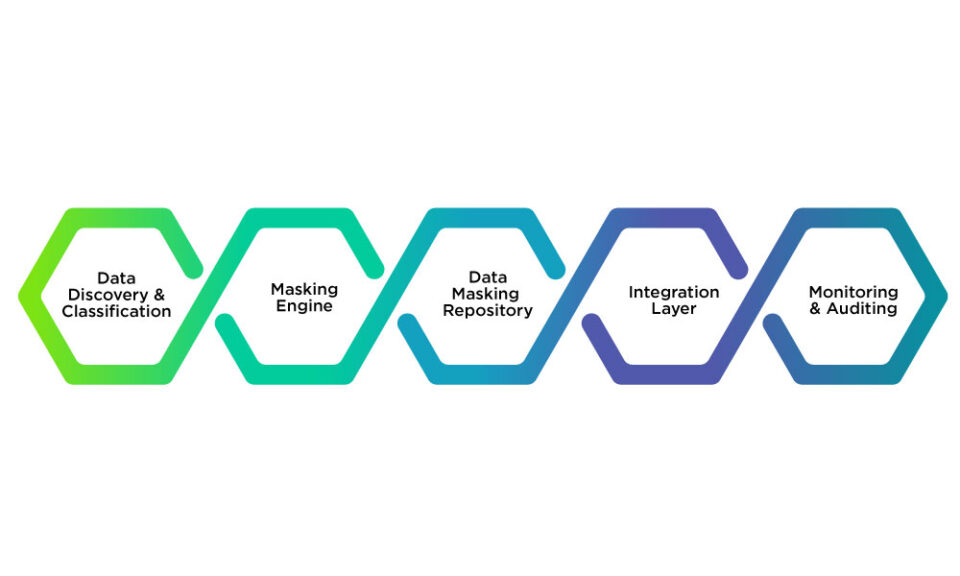
Basically, data masking refers to architecture that protects sensitive information by changing it into a form that is of no relevance and can be used for a number of purposes without giving away the actual details. It would basically contain some major components that are,
- Data Discovery and Classification: This is the initial phase that discovers and classifies the sensitive data of the organization's database. It involves automated tools and algorithms that would scan through the databases for detection and further categorization according to predefined rules and patterns. For example, a financial institution would make use of data discovery tools to identify and classify customer account numbers, credit card information, and transaction details.
- Masking Engine: This is the heart of the architecture; it would use the masking rules to transform sensitive data into masked data. It would consist of Rule Engine, Masking Algorithms, and Data Transformation modules. For example, a health provider may use a masking engine to mask a patient's name and social security number against some fictitious but realistic values.
- Data Masking Repository: This repository maintains the organization of the masking rules, configuration, and metadata. It can be a database or a file-based system that maintains management for the masking policies and the audit logs. For example, a retailer may maintain a repository containing the masking rules on customer purchasing histories and data from their loyalty programs.
- Integration Layer: This layer enables seamless integration of the data masking solution with existing databases, applications, and workflows. This layer consists of connectors, APIs, and middleware. For instance, an e-commerce platform integrating a data masking solution with a CRM system to secure customer information during transactions.
- Monitoring and Auditing: This module tracks data masking activities for compliance and security by making an audit record. It contains logging mechanisms, audit trails, and reporting tools. For example, monitoring and auditing tools could be used by a government agency to log access to masked citizen data to achieve compliance with personal data protection regulations.
Data Masking Techniques:
There are several techniques for data masking, each with its different advantages and use cases: substitution, shuffling, encryption, masking out, and tokenization.
- Substitution: This will involve the replacement of sensitive data with realistic but fictional values. For example, a bank might test with randomly generated names instead of actual customer names, the test data will still be useful for the testing to be done but the actual information will remain safe.
- Shuffling: Shuffling randomly changes the order of data in a column. For example, a telecommunications company would arrange the order of phone numbers in its dataset in a random manner so that the privacy of customers is retained but the overall structure remains the same.
- Encryption: This is where sensitive data is transformed into a safe format that can only be decrypted by the intended party. For instance, an online retailer can encrypt credit card numbers with a secure encryption algorithm to keep them safe during transactions.
- Masking Out: One of the substitution techniques that replace sensitive data either with a constant or a pattern. For example, a healthcare provider might mask all but the last four digits of a patient's social security number with asterisks to protect the identity of the patient; for instance, *--1234.
- Scrambling: Scrambling is simply a process whereby characters can be mixed up in a data field with an aim of obscuring their original value. This often applies to alphanumeric data, such as names and addresses. For example, a company may scramble the names of employees in a dataset to protect their identities during data analysis.
- Nulling Out or Deleting: The technique involves replacing sensitive data with NULL values or deleting them. This approach is useful in scenarios where the data is not necessary for the intended use. For instance, a company might null out social security numbers in a dataset used for training purposes.
- Data Variance: Differential privacy involves the addition of variance to data values in a way that masks original information. The technique is one of the common information-preserving techniques in the data analysis domain, so that the details pertaining to an individual transaction are protected. For example, a marketing firm might add a variance related to customer purchase amounts.
- Tokenization: It is a process of replacing sensitive data with a token that can be used later for referencing the original data within a secure tokenization system. For example, a payment processor will replace the credit card number with a unique token for transactions without revealing the real card number.
Good Practices in Data Masking:
To ensure the effectiveness of a data masking solution, organizations should follow these best practices:
In-depth Data Discovery:
- Run an organization-wide data discovery to find out all locations that store sensitive data.
- Use automated tools to scan databases and classify data based on sensitivity.
Define Clear Masking Policies
- Set up clear masking policies and rules with respect to data sensitivity and regulatory requirements.
- Ensure consistency in the rules applied to masks across every environment.
Keep Masking Rules Updated
- Masking rules should be reviewed for applicability to new data types and changed regulatory requirements regularly.
- Ensure that masking rules align with the best security practices in all respects.
Implement Role-Based Access Control (RBAC)
- Access restrictions and data concealment from user information based on roles and duties to users.
- Ensure that only authorized users can modify masking rules and access masked data.
Monitor and Audit Masking Activities
- Enable monitoring and audit mechanisms for tracking data masking activities.
- Those audit logs must be regularly reviewed according to the data privacy laws.
Test Masked Data
- Test the effectiveness of data masking by running full tests.
Ensure masked data remains meaningful for development, testing, and analytics.
Summing UP!
Data masking is a major domain in an organization's data privacy and security strategy. It represents the process an organization undertakes to secure its sensitive data through a good data masking architecture to ensure the data remains usable, meets the intended use, and are well secured. Proper techniques, tools, and management processes of data masking can strongly enable an organization at a high scale towards complete compliance with data privacy regulations and protecting valuable information assets.
If you have any more questions or need further details, visit us at WisdomPlexus!
Also Read:
Know about these Data Masking Examples that can benefit any business


